
.png)
Every organization has the same problem. They just describe it differently depending on which team you ask.
The SOC team says: "We can't see network logs. The NOC owns those."
The NOC team says: "Security incidents take forever because we're waiting on the SOC to pull endpoint data."
Compliance says: "Every audit requires pulling reports from six different systems. It takes weeks."
IT Ops says: "We troubleshoot the same issues repeatedly because we can't see what security has already investigated."
Same underlying problem. Different symptoms.
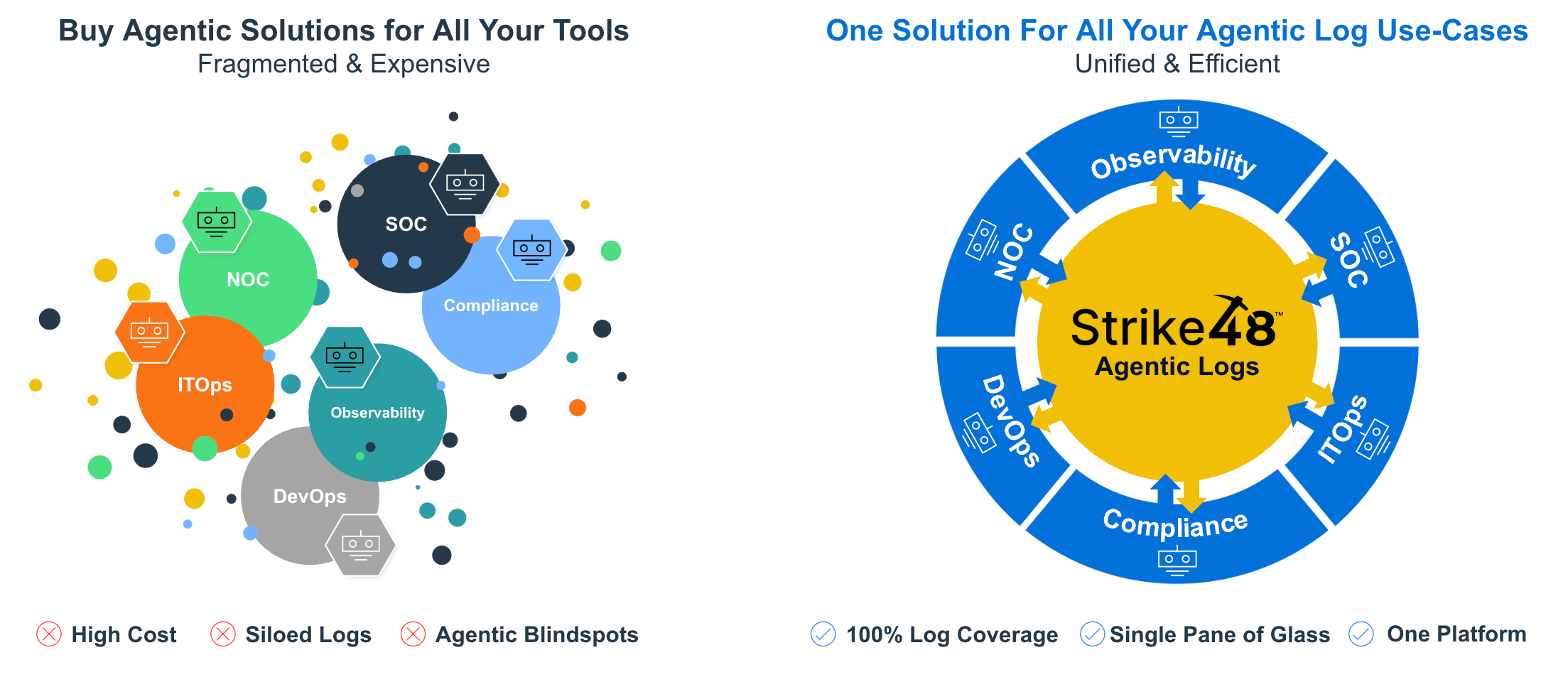
Your logs are scattered across tools that don't talk to each other. Each team built or inherited their own logging infrastructure—security events in the SIEM, application performance in observability platforms, network data in flow collectors, compliance evidence in yet another system. These silos made sense when each team worked independently. They break down the moment anyone needs to work across boundaries.
And they completely break down when you try to deploy AI agents.
Take a typical mid-size enterprise. Where do logs actually live?
Security: Splunk, Sentinel, or QRadar for SIEM. CrowdStrike or SentinelOne for EDR. Proofpoint or Mimecast for email security. Zscaler or Palo Alto for network security. Each with its own console, query language, and retention policy.
IT Operations: Datadog, New Relic, or Dynatrace for APM. PagerDuty or ServiceNow for incident management. CloudWatch, Azure Monitor, or GCP Operations for cloud infrastructure. Cisco or Arista for network operations.
Compliance: GRC platforms for policy management. DLP tools for data protection. Identity governance systems for access certification. Separate audit log repositories because the primary systems don't retain long enough.
That's fifteen-plus distinct systems before counting cloud-specific logging, SaaS application logs, or legacy on-prem infrastructure. Each one is a silo. Each boundary creates friction. And within each silo, cost pressure creates another layer of fragmentation: hot versus cold storage. Most SOC teams keep only 90 days of searchable data in their SIEM before shifting older logs to cold storage. When an investigation requires historical context, analysts wait for data to warm up—or simply work without it.
When the SOC investigates a potential breach, they often can't see the network logs that would confirm lateral movement. When IT Ops troubleshoots an outage, they can't see the security events that might indicate a DDoS. When compliance runs an audit, they spend more time collecting evidence than analyzing it.
The tools work fine in isolation. The organization doesn't operate in isolation.
Here's where silos become a critical roadblock: AI agents can only work with data they can access.
Most "agentic" security products operate within a single platform. They can investigate alerts in that platform, query data in that platform, correlate events in that platform. Step outside the platform boundary and the agent goes blind.
An AI agent in Sentinel can't see your Splunk data. An agent in Splunk can't query your Snowflake security lake. An agent in any single tool can't investigate across the full attack surface.
This isn't a feature limitation—it's an architectural constraint. These agents are built on platforms designed before cross-silo visibility was the problem to solve.
The result: your AI agents inherit exactly the same blind spots your analysts have. They just hit those walls faster.
Agentic Log Intelligence is designed to break down those siloes. Strike48 is a layer that sits above your existing silos and queries across all of them.
The architecture is deliberately different from traditional platforms:
Query federation: Strike48 connects to your existing systems—SIEMs, observability platforms, cloud storage, data lakes—and queries them directly. Data stays where it lives. Agents access it wherever it is.
Automatic translation: Agents work in a unified query abstraction. When they need Splunk data, the platform translates to SPL. Microsoft data? KQL. Snowflake? SQL. Analysts and agents interact in natural language. The platform handles the syntax.
Cross-silo correlation: An investigation that spans security, network, and application logs doesn't require manual pivoting between tools. The agent queries all relevant sources, correlates results, and produces a unified view.
This means your SOC can see NOC data during an investigation. Your NOC can see security context during troubleshooting. Compliance can pull evidence from everywhere without waiting on six different teams.
The silos still exist as storage and collection infrastructure. They stop existing as investigation boundaries.
Security gets most of the attention in "unified visibility" conversations, but IT Operations benefits equally.
Consider a production outage. Traditional troubleshooting:
With a unified layer:
Same data sources. Fraction of the time. No manual pivoting between tools.
The NOC use case is fundamentally the same as the SOC use case: investigate across sources, correlate findings, resolve faster. The only difference is which sources matter for which type of incident.
Compliance teams rarely show up in "unified logging" discussions, which is strange because they're often the most impacted by silos.
Audit evidence lives everywhere. Access logs in the identity system. Change records in the ITSM platform. Security events in the SIEM. Application logs in observability tools. Data access logs in the DLP system.
Every audit cycle, compliance teams submit requests to every team that owns a system. Every team has different SLAs, different export formats, different retention periods. Collecting evidence takes longer than analyzing it.
Strike48's unified layer changes the dynamic:
When auditors ask "show me all privileged access to production systems for the past 90 days," the answer doesn't require three teams and two weeks. The agent queries identity, endpoint, cloud, and application logs simultaneously and produces the report in minutes.
Building a unified layer doesn't mean replacing every logging system. That's neither practical nor necessary.
Phase 1: Connect Identify the systems that contain data relevant to cross-functional investigations. Connect Strike48 to each one. No data migration—just API connections and query access.
Phase 2: Use Cases Start with specific cross-silo use cases. Security investigations that require network data. Outage troubleshooting that requires security context. Audit evidence collection across systems. Prove value in focused scenarios.
Phase 3: Expand Add additional systems as use cases emerge. The architecture scales horizontally—each new connection expands what agents can see and investigate.
The goal isn't consolidating all logs into one platform. It's making all logs accessible from one layer. Storage stays distributed. Investigation becomes unified.
See unified querying across silos. Request a demo to watch Strike48 agents investigate incidents across Splunk, Datadog, and cloud data lakes—one investigation, multiple sources, no manual pivoting.